


פרויקטי גמר - תואר ראשון בהנדסת חשמל (B.Sc) - לעמוד בחזית הטכנולוגיה - התמחות בעיבוד אותות תשפ"ד
הרקע לפרויקט:
A key ingredient of deep learning is (stochastic and nonconvex) optimization. Most popular optimizers include a momentum term. Yet, there are two common approaches to construct a momentum term that are somewhat contradicting. One of them can be understood as interpolation and the other one as extrapolation. The goal of the project is to provide insights (at least on an empirical level) on the pros and cons of each approach and whether one approach dominates the other, or is there a place for an intermediate approach.
מטרת הפרויקט:
The goal of the project is to provide insights (at least on an empirical level) on the pros and cons of each approach and whether one approach dominates the other, or is there a place for an intermediate approach.
תכולת הפרויקט:
Extensive experimentation on common deep neural networks and optimizers with different momentum approaches. Gaining insights on the pros and cons of each approach and whether one approach dominates the other. Potentially developing a new successful optimizer for deep learning and/or establishing theoretical reasoning (in a simplified setting) for the empirical observations.
קורסי קדם:
מבוא ללמידת מכונהֿ, אופטימיזציה, רמה גבוה באלגברה לינארית וחדו״א מרובת משתנים.
מקורות:
הרקע לפרויקט:
נבחן שיטות שונות ל״כיול״ מודלים נלמדים כך שלתחזיות שלהם ילווה מדד אי-ודאות בעל משמעות או הבטחה סטטיסטית
מטרת הפרויקט:
ישנם שני סוגי כיול נפוצים -- האחד ״סטנדרטי״ ויוריסטי שמכוונן את ערכי הsoftmax כדי שיתאימו להסתברות הדיוק, והשני מגובה תיאורטית מפיק סט של מחלקות שמכסה את המחלקה הנכונה בהסתברות נדרשת. נבחן את יחסי ההשפעה של שתי השיטות זו על זו ואת ההבדלים ביניהן.
תכולת הפרויקט:
ניסויים שיראו מה ההשפעה של שתי שיטות הכיול זו על זו ואת ההבדלים ביניהן. מחקר תיאורטי האם הבטחות תיאורטית של כיול ע״י כיסוי יכולות להיות מנוצלות ע״י שילובו בכיול הסטנרטי. בדיקת המצב ברגרסיה ולא רק בקלאסיפיקציה.
קורסי קדם:
הסתברות, מבוא ללמידת מכונה, שיערוך והסקה סטטיסטית
מקורות:
https://arxiv.org/abs/2107.07511
הרקע לפרויקט:
במשימת הפרדת הדוברים בהינתן הקלטה בה מספר רב של דוברים המדבים בו זמנית נרצה להפריד ולשערך כל אחד מן הדוברים. מנגד, במשימת חילוץ דובר רצוי נרצה אדם ספציפי בהינתן ידע מוקדם על אדם זה. וידאו של השיחה, מיקום הדובר או הקלטה מוקדת של אדם ספציפי, כל אלה יכולים לשמש כאות ייחוס עבור חילוץ הדובר.
מטרת הפרויקט:
מטרת הפרויקט הינה לבסס אלגוריתם יציב לצורך שיערוך והפרדת הדובר
תכולת הפרויקט:
על הסטודנטים יהיה לאמן מודל מבוסס AI לצורך שיערוך הדובר הרצוי
קורסי קדם:
עיבוד ספרתי של אותות 2, אלגוריתמים סטטיסטיים לעיבוד אותות
דרישות נוספות:
למידה עמוקה
מקורות:
https://arxiv.org/abs/2303.07072
הרקע לפרויקט:
Generative models have recently gained a lot of attention thanks to their successful application in many fields. Deep generative models for audio, learn, directly or implicitly, the distribution of mixtures, possibly conditioning on additional data such as text. Various general-purpose generative models, such as autoregressive models, GANs , and diffusion models, have been adapted for use in the audio field.
מטרת הפרויקט:
In this project, the students will build a diffusion-based generative model capable of music synthesis by learning the score of the joint probability density of sources sharing a context.
תכולת הפרויקט:
הסטודנטים יבנו ויממשו רשת דפיוזית שמייצרת דוגמאות מוזיקה. מוצאי הרשת ייבחנו בשיטות המקובלות וישוו לשיטות מתחרות. בנוסף, נרצה לשלב יכולת הפרדה של הרשת למקטעים מיקס של מוזיקה.
קורסי קדם:
- למידה עמוקה
- עיבוד אותות ספרתי 1+2 (2, במקביל)
- למידת מכונה
דרישות נוספות
- תכנות בpython
- שימוש בlinux
מקורות:
Multi-Source Diffusion Models for Simultaneous Music Generation and Separation https://arxiv.org/pdf/2302.02257.pdf
הצלחת הפעלת רשת המאפשרת בו זמנית מספר משימות שונות
הרקע לפרויקט:
Find Room Impulse Response (RIR) of specific room is an important task for many uses in audio signal processing. Measurements of RIR is expensive in the sense of time and equipment. Many RIR generators was developed trying to simulate the room behavior using different methods. We present a method for improving the quality of synthetic room impulse responses for far-field speech recognition. We bridge the gap between the fidelity of synthetic room impulse responses (RIRs) and the real room impulse. Given a synthetic RIR in the form of raw audio, we translate it into a real RIR.
מטרת הפרויקט:
בפרויקט נממש מערך לסופר רזולוציה של RIR ע"י למידה עמוקה. נשתמש במודל GAN כדי לקחת RIR שנוצר ע"י סימולציה, וניצור ממנו RIR שמתנהג כמו RIR מציאותי. בנוסף, ננסה נשתמש במודל כדי ליצור RIR גם במקומות נוספים שבהם לא קיימת לנו סימולציה. לאחר מכן נוכן להשתמש במודל זה על מנת לשפר מדידות קיימות של RIR, גם במקומות נוספים בחדר שלא קיימים לנו מדידות בהם.
תכולת הפרויקט:
- סקירה והבנה של שיטות שונות ליצירת RIR בצורה סינטטית.
- מציאת או יצירת Data-Base של מדידות RIR.
- מימוש בpython של מערכת למידה עמוקה. מודל מסוג של GAN.
- אימון המודל ע"מ:
לשפר את הRIR הסינטטי.
סופר רזולוציה – יצירת RIR גם במקומות שבהם אין לנו הקלטת RIR.
קורסי קדם:
- קורס עיבוד ספרתי 2
- קורס למידה עמוקה
(במהלך שנה ד')
דרישות נוספות:
- קורס למידת מכונה
- תכנות בpython.
מקורות:
- Anton Ratnarajah, Shi-Xiong Zhang, Meng Yu, Zhenyu Tang, Dinesh Manocha, Dong Yu, ”FAST-RIR: FAST NEURAL DIFFUSE ROOM IMPULSE RESPONSE GENERATOR”, https://arxiv.org/abs/2110.04057
- Anton Ratnarajah, Zhenyu Tang, Dinesh Manocha, “IR-GAN: Room impulse response generator for far-field speech recognition”, https://arxiv.org/abs/2010.13219
הרקע לפרויקט:
בשנים האחרונות מתרחב השימוש בכלי תוכנה מבוססים קוד פתוח.
מטרת הפרויקט להנגיש ולפתח בצורה גרפית קוד אשר יהפוך באופן אוטומטי לתוכנית שתרוץ על המחשב שלנו. גישת פיתוח זו מקצרת באופן משמעותי את זמני הפיתוח של אב טיפוס של המוצרים.
מטרת הפרויקט:
נגישות לכלי תוכנה לפיתוח אלגוריתמי DSP תורמת לקיצור זמנים בפיתוח של אב טיפוס של המוצר.
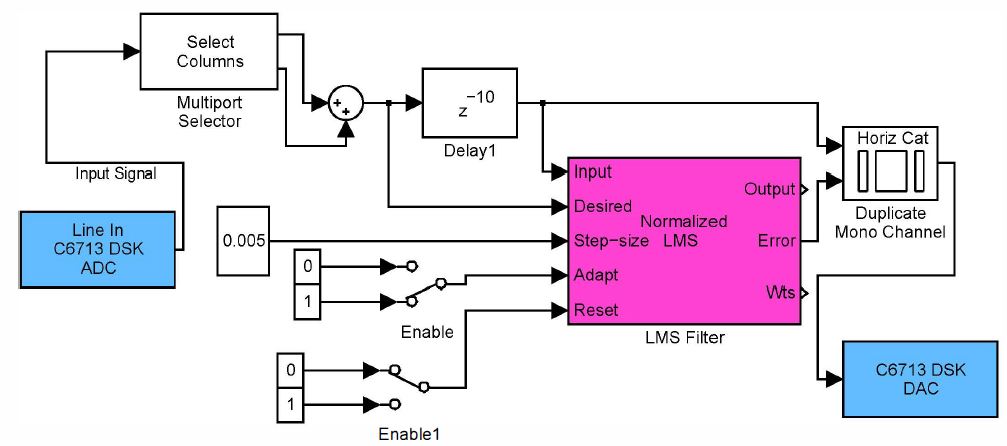
סביבות עבודה גרפיות נפוצה ל FAST PROTOTYPING הינה Matlab/SIMULINK [ 1],
ראה מודל סימולינק לדוגמה בלינק :
https://www.eng.biu.ac.il/~pinit/Proj_2023/SIMULINK_example.JPG ).
רשיון מטלב עם DSP TOOLBOX יכול להגיע למאות או אלפי דולרים לעמדה בודדת בארגון.
שימוש בכלי פיתוח שהם Freeware software יכול להנגיש את הכלים לקהל מטרה רחב יותר.
כמו כן, כלים שהם Freeware software יכולים להוות בסיס להוראה של מעבדת DSP ותקשורת בקמפוסים בעלי יכולות כלכליות מוגבלות.
תכולת הפרויקט:
בפרויקט זה נמשיך לפתח DSP TOOLBOX בנושאים מגוונים דוגמת סינון, משפט הדגימה, אינטרפולציה ודצימציה וסינון אדפטיבי.
במסגרת הפרויקט יבחנו מספר סביבות עבודה גרפיות [2-5] לצורך החלפת Matlab/SIMULINK למימוש FAST PROTOTYPING [1]
קורסי קדם:
- עיבוד ספרתי 1
- אלגוריתמים סטטיסטיים
מקורות:
- Gannot, S., & Avrin, V. (2006, September). A Simulink© and Texas instruments C6713® based digital signal processing laboratory. In 14th European Signal Processing Conference, 2006. (https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=7071073 )
- https://www.scilab.org/software, an open-source matlab + Simulink (scilab + xcos)
- https://github.com/severin-lemaignan/boxology
- https://github.com/node-red/node-red
- https://github.com/leon-thomm/Ryven (Python)
הרקע לפרויקט:
בפרויקט זה תמומש שיטה לאיתור מקורות בחלל תלת מימדי(3D) המבוססת על שיטת החישה של עטלפים. חיפוש ואיתור מקורות בחלל תלת מימדי הוא מאתגר בשל העומס החישובי המוטל על המערכת בזמן אמת. לדוגמא, אלגוריתם MUSIC מבוסס על סריקה של כל הנקודות האפשריות במרחב ומציאת הנקודה האופטימאלית אשר מביאה למינימום את פונקציית המחיר. מסתבר כי עטלפים סורקים את המרחב שלפניהם באופן מהיר ביותר על ידי שיטות איטרטיביות מתוחכמות. בפרויקט זה ננסה להתחקות אחר השיטות האלו ולייעל ולקצר את תהליך האיתור.
מטרת הפרויקט:
התוצר הסופי הינו אלגוריתם ממומש ועובד לשיפור משמעותי של זמן הריצה של מערכות איתור מקורות בחלל תלת מימדי.
תכולת הפרויקט:
- בשלב ראשון ננסה לנסח אלגוריתם המייעל את תהליך איתור המקורות בהתבסס על שיטת MUSIC וחישת עטלפים
- בניית סימולציית MATLAB/PYTHON.
- כתיבת האלגוריתם ופתרון בעיות של זמן אמת
- עריכת הקלטות ובחינת ביצועים
קורסי קדם:
- עיבוד אותות ספרתי
- עיבוד אותות סטטטיסטי
- עיבוד אותות מרחבי
מקורות:
הרקע לפרויקט:
במבנה מורכב של מספר מערכי מיקרופונים המקושרים זה לזה (הנקראת רשת מיקרופונים מבוזרת), רק מספר חלקי של מערכים תורמים תרומה משמעותית למשימות שיפור הדיבור. שימוש במערכים האינפורמטיביים ביותר הללו במקום ברשת כולה לא רק מונע צריכת אנרגיה מיותרת אלא גם מאריך את חיי המקרופונים. לשם כך, מוצעת שיטת בחירת מערכים לשיפור דיבור. קבוצת המשנה הטובה ביותר של מערכי מיקרופון נקבעת על ידי מיקסום יחס האות לרעש (SNR), תוך שמירת המקרופונים המופעלים מחוברים זה לזה. השיטה המוצעת יכולה להשיג את תת הרשת האופטימלית בסביבות רועשות ומהדהדות.
מטרת הפרויקט:
מימוש השיטה לבחירת המערכים האינפורמטיביים ביותר מתוך כלל הרשת לצורך שיפור דיבור ובדיקתה ע"י סט הקלטות.
תכולת הפרויקט:
- בשלב ראשון ננסה לנסח את האלגוריתם המוצע.
- בניית סימולציית MATLAB/PYTHON.
- כתיבת האלגוריתם ופתרון בעיות של זמן אמת
- עריכת הקלטות ובחינת ביצועים
קורסי קדם:
- עיבוד אותות ספרתי
- עיבוד אותות סטטטיסטי
- עיבוד אותות מרחבי
מקורות:
1. https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=10043687&casa_toke…
הרקע לפרויקט:
Direction of arrival (DOA) estimation is an important topic in microphone array processing. Conventional methods work well in relatively clean conditions but suffer from noise and reverberation distortions. Recently, deep learning-based methods show the robustness to noise and reverberation. However, the performance is degraded rapidly or even model cannot work when microphone array structure changes. So, it has to retrain the model with new data, which is a huge work. In this paper, we propose a supervised learning algorithm for DOA estimation combining convolutional neural network (CNN) and long short-term memory (LSTM).
In our problem we have complex input and output. Therefore, on next stage we try to change the Network architecture from CNN and LSTM to Complex valued Neural Network.
מטרת הפרויקט:
בפרויקט נפתור את בעיית איכון כיוון הדובר בעזרת רשת נוירונים מרוכבת. בשלב הראשון נממש עיבוד מקדים לרשת, ע"מ לבטל את התלות בסוג המערך ובמספר המיקרופונים. כך נקבל features מרוכב. לאחר מכן נבנה רשת GRU מרוכבת, ונבדוק את ביצועי הרשת.
תכולת הפרויקט:
- סקירה והבנה של בעיית מציאת כיוון דובר, ושל רשתות נוירונים מרוכבות.
- מימוש בpython של העיבוד המקדים לרשת.
- מימוש מערכת למידה עמוקה מרוכבת מסוג GRU.
- אימון המודל ע"מ שיפור הדיוק של זיהוי הכיוון גם בסביבה רועשת ומהדהדת.
קורסי קדם:
- קורס עיבוד ספרתי 2
- קורס למידה עמוקה
(במהלך שנה ד')
דרישות נוספות:
- קורס למידת מכונה
- תכנות בpython.
מקורות:
- Charles H. Knapp and G. Clifford Carter, "The Generalized Correlation Method for Estimation of Time Delay"
- Qinglong Li, Xueliang Zhang and Hao Li, “ONLINE DIRECTION OF ARRIVAL ESTIMATION BASED ON DEEP LEARNING”
- Mhd Modar Halimeh, Thomas Haubner, Annika Briegleb, Alexander Schmidt, Walter Kellermann, “COMBINING ADAPTIVE FILTERING AND COMPLEX-VALUED DEEP POSTFILTERING FOR ACOUSTIC ECHO CANCELLATION”
הרקע לפרויקט:
This project focuses on solving the cocktail party problem, which involves separating multiple speakers who are talking simultaneously using a single microphone. The proposed algorithm utilizes a deep learning model in a vector space that represents independent speakers. By distinguishing between speaker masks and leveraging negative sampling techniques, the algorithm learns to separate speakers effectively. It offers potential applications in areas such as automatic speech recognition.
מטרת הפרויקט:
The goal of this project is to develop an algorithm that can successfully address the "cocktail party problem" by effectively separating multiple speakers who are speaking simultaneously using only a single microphone
תכולת הפרויקט:
- Watch the lectures in youtube - Stanford University CS231n, Spring 2017
- Read the paper.
- Download the dataset
- Integrate a more advanced model as the central component of the network, replacing the traditional RNN approach
- Train the model
- Expect to satisfactory results :))
The project will be implemented in Pytorch
קורסי קדם:
Deep Learing, Python and Pytorch
דרישות נוספות:
Watching related videos on YouTube
מקורות:
We will implement the following paper:
Monaural Audio Speaker Separation with Source Contrastive Estimation
הרקע לפרויקט:
The problem of jointly estimating the total surface area, volume, frequency-dependent reverberation time, and mean surface absorption of a room in a blind manner is studied in this paper. This knowledge of the geometrical and acoustical parameters of a room can be beneficial for applications such as audio augmented reality, speech dereverberation, or audio forensics.The proposed approach utilizes two-channel noisy speech recordings from multiple unknown source-receiver positions.
The proposed model outperforms a recently proposed blind volume estimation method on the considered datasets.
מטרת הפרויקט:
The project focuses on leveraging two-channel noisy speech recordings from multiple unknown source-receiver positions. By developing a novel convolutional neural network architecture that utilizes both single and inter-channel cues, the goal is to accurately estimate the target parameters in a blind manner.
תכולת הפרויקט:
1. Watch the lectures in youtube - Stanford University CS231n, Spring 2017
2. Read the paper
3. Download the dataset
4. Build the model
5. Train the model
6. Expect to satisfactory results :))
The project will be implemented in Pytorch
קורסי קדם:
Deep Learing, Python and Pytorch
דרישות נוספות:
Watching related videos on YouTube
מקורות:
We will implement the following paper:
Blind Room Parameter Estimation Using Multiple Multichannel Speech Recordings
הרקע לפרויקט:
Given a multi-microphone recording of an unknown number of speakers talking concurrently, this project simultaneously localizes the sources and separate the individual speakers. The core of this method is a deep network in the waveform domain, which isolates sources within an angular region θ ± w/2, given an angle of interest θ and angular window size w. By exponentially decreasing w, we can perform a binary search to localize and separate all sources in logarithmic time. This algorithm allows for an arbitrary number of potentially moving speakers at the same time, including more speakers than seen during training.
Automating this process of speech separation has many valuable applications, including assistive technology for the hearing impaired, improvement of Automatic Speech Recognition(ASR) systems, or better transcription of spoken content in noisy in-the-wild Internet videos (Speech to Text).
מטרת הפרויקט:
The purpose of this project is to develop a method that can effectively localize and separate individual speakers in a multi-microphone recording where multiple speakers are talking simultaneously.
תכולת הפרויקט:
1. Watch the lectures in youtube - Stanford University CS231n, Spring 2017
2. Read the paper
3. Download the dataset
4. Build the model
5. Train the model
6. Expect to satisfactory results :))
The project will be implemented in Pytorch
קורסי קדם:
Deep Learing, Python and Pytorch.
דרישות נוספות:
Watching related videos on YouTube
מקורות:
We will implement the following paper:
The Cone of Silence:Speech Separation by Localization
הרקע לפרויקט:
Recently, the speech separation (SS) task has made significant advancements due to deep learning techniques. However, separating target signals from noisy mixtures remains challenging as neural models can mistakenly assign background noise to each speaker. This project propose a noise-aware SS method called NASS, which aims to enhance the speech quality of separated signals in noisy conditions.
Specifically, NASS treats background noise as an independent speaker and predicts it alongside other speakers using a mask-based approach. Patch-wise contrastive learning is employed at the feature level to minimize the mutual information between the predicted noise-speaker and other speakers. This allows for the suppression of noise information in the separated signals.
מטרת הפרויקט:
The purpose of this project is to enhance the speech quality of separated signals in noisy conditions.
תכולת הפרויקט:
1. Watch the lectures in youtube - Stanford University CS231n, Spring 2017
2. Read the paper
3. Download the dataset
4. Build the model
5. Train the model
6. Expect to satisfactory results :))
The project will be implemented in Pytorch
קורסי קדם:
Deep Learing, Python and Pytorch
דרישות נוספות:
Watching related videos on YouTube
מקורות:
We will implement the following paper:
Noise-aware Speech Separation with Contrastive Learning
הרקע לפרויקט:
בתוך תחום למידה עמוקה, מודלים גנרטיביים תופסים מקום נרחב והובילו לפיתוחים משמעותיים בתחום כמו: chatGPT שעורר הדים רבים. גישה חדשה בתוך תחום זה היא שימוש במודלים דפיוזים גנרטיביים, בהם נתמקד בפרויקט זה לצורך ניקוי ושיפור איכות אות דיבור.
מטרת הפרויקט:
מטרת הפרויקט היא לאמן רשת נוירונים שמבצעת speech enhancement בגישה גנרטיבית ע"י מודל דיפיוזי. הרשת תבחן גם על אותות "עולם אמיתי" והקלטות בתנאי מעבדה על מנת לבחון את יכולת ההכללה שלה.
תכולת הפרויקט:
- הקלטת דטה במעבדה, איסוף דטה אמיתי מהאינטרנט
- הפעלת טסט על הדטה החדש ושיפור ביצועי הרשת עליו
קורסי קדם:
- עיבוד אותות ספרתי 1
- אלגוריתמים סטטיסטיים לעיבוד אותות 1
- למידת מכונה
במקביל:
- עיבוד אותות ספרתי 2
- אלגוריתמים סטטיסטיים לעיבוד אותות 2
- למידה עמוקה
דרישות נוספות:
- תכנות בpython
- היכרות עם לינוקס
מקורות:
- J. Richter et al., “Speech enhancement and dereverberation with diffusion-based generative models,” Arxiv.org. [Online]. Available: http://arxiv.org/abs/2208.05830.
הרקע לפרויקט:
Generative models have recently gained a lot of attention thanks to their successful application in many fields. Unlike in other sub-fields of the audio domain (e.g., speech), sources present in musical mixtures (stems) share a context given their strong interdependence. Therefore, this separation process is a challenging task.
מטרת הפרויקט:
In this project, the students will build a diffusion-based generative model capable of source separation by learning the score of the joint probability density of sources sharing a context.
תכולת הפרויקט:
הסטודנטים יבנו ויממשו רשת דפיוזית שמפרידה מיקס של מוזיקה. מוצאי הרשת ייבחנו בשיטות המקובלות וישוו לשיטות מתחרות. בנוסף, נרצה לשלב ברשת יכולת של ייצור דוגמאות מוזיקה חדשות.
קורסי קדם:
- עיבוד אותות ספרתי 1+2 (2, במקביל)
- למידת מכונה
- למידה עמוקה (במקביל)
דרישות נוספות:
- תכנות בpython
- שימוש בlinux
מקורות:
- G. Mariani, I. Tallini, E. Postolache, M. Mancusi, L. Cosmo, and E. Rodolà, “Multi-source diffusion models for simultaneous music generation and separation,” Arxiv.org. [Online]. Available: http://arxiv.org/abs/2302.02257.
הרקע לפרויקט:
יכולת התאמת קטעי אדיו בעלי אורכים שונים מסביבה מהודהדת לנקייה
מטרת הפרויקט:
יכולת התאמה עבור אלגוריתם echo cancellation
תכולת הפרויקט:
- יצירת דאטא
- רשת נוירונים
- אלגוריתם מסתגל להורדת אקו
קורסי קדם:
- עיבוד אותות סטטיסטיים 2
- למידה עמוקה
מקורות:
ישנן מספר עבודות בתחום
הרקע לפרויקט:
בסביבה רועשת של מספר דוברים אנו נרצה להתמקד בהקלטת הדיבור של דובר רצוי אשר נמצא בכיוון מסויים ולהתעלם ממידע אשר מגיע מכיוונים לא רצויי. בפרויקט יבחנו פיתרונות קלאסיים לבעיה וגם יבחנו פיתרונות מבוססי למידה עמוקה
מטרת הפרויקט:
התוצר הסופי הינו אלגוריתם ממומש ועובד עם חומרה של מערך מיקרופונים מחובר למחשב נייד [1,2]
תכולת הפרויקט:
- בניית סימולצייה של מערך מיקרופונים/דוברים ומקורות רעש
- בדיקת ביצועים של ה Beam Former
- מימוש האלגוריתם בזמן אמת
- עריכת ניסויים בחדר האקוסטי ובחינת ביצועים של המערכת
קורסי קדם:
- למידה עמוקה
- עיבוד אותות ספרתי
- עיבוד אותות סטטטיסטי
מקורות:
הרקע לפרויקט:
פסקה המתארת את הטכנולוגיה הרלוונטית לפרויקט ואת משמעות הפרויקט בהקשר זה ה Chatbots [ 1,2,3] פולשים לחיינו ואנו נפתח מערכת מערכת לשילובם במחשבים נידים
כיום קימים מגוון של Chatbots, בפרויקט זה נסקור את הקיים בשוק ונתמקד בעלות מיטבית תוך שמירה על רמת ביצועים סבירה [3] בהמשך תבחן גם אפשרות לשילוב המערכת ברובוט חברתי [7] אשר משמש ככוח עזר בבית חולים.
מטרת הפרויקט:
בפרויקט זה נפתח מערכת שמע ובינה מלאכותית הכוללת:
- הרכשת הדיבור בעזרת מיקרופון/מערך מיקרופונים [6]
- עיבוד ראשוני של אות הדיבור (יבחן שילוב אלגוריתם ניקוי רעשים שפותח במעבדה)
- זיהוי דיבור (העברת שמע לטקסט) [4]
- צ'אטבוט
- מערכת text-to-speech שתיצור אות דיבור מהטקט שחיבר הצ'אטבוט [5]
- שידור הדיבור ברמקול.
הדגש בפרויקט יהיה על שילוב הצ'אטבוט.
תכולת הפרויקט:
- בחירת chatbot לפרויקט ולהגדירו כמומחה לתחום מסויים – למשל : אינטראקציה עם זקנים , מועדון של אוהדי מכבי תל אביב וכו
- הפעלת ASR & TTS
- שילוב מערך מיקרופונים
- בחינת ביצועים של המערכת
קורסי קדם:
- פיתון
דרישות נוספות:
- פיתון ברמה גבוהה
מקורות:
- https://openai.com/blog/introducing-chatgpt-and-whisper-apis
- https://bard.google.com/chat
- https://lmsys.org/blog/2023-03-30-vicuna/
- https://cloud.google.com/speech-to-text
- https://cloud.google.com/text-to-speech?hl=en
- Microphone array HW site : https://www.seeedstudio.com/ReSpeaker-Mic-Array-Far-field-w-7-PDM-Micro… , https://wiki.seeedstudio.com/ReSpeaker_Mic_Array/
- https://pal-robotics.com/robots/ari/
הרקע לפרויקט:
פסקה המתארת את הטכנולוגיה הרלוונטית לפרויקט ואת משמעות הפרויקט בהקשר זה
מודלים של למידה עמוקה מצריכים משאבים רבים של זיכרון וכח מיחשוב חזק. פרויקט זה עוסק בניתוח ואופטימיזציה של מערכות למידה עמוקה בזמן האימון והשימוש במודלים.
מטרת הפרויקט:
מטרת הפרויקט הנה להקטין את גודל המודלים ולהקטין את העומס החישובי על ה GPU תוך שמירה על ביצועים (BIT EXACT ). במהלך הפרויקט יבחנו ביצועים של מספר מודלים מסחריים (התלמידים יעשו סקר ספרות על שוק ה [1-3] CHATBOTS), מודלים אשר פותחו במעבדה ומודלים שיפותחו במהלך הפרויקט.
בפרויקט נבחן ביצועים של המערכת כתלות בגודל משתנה המודל (double vs. Int16 וכו') ומספר הפרמטרים ביחס למודל המקורי.
כמו כן תבדק סיפריית JIT לפיתון [8-10] לצורך שיפור ביצועים ב CPU ויבחנו כלי PROFILING ל CPU[11]
תכולת הפרויקט:
-
פירוט של מטלות הסטודנטים בפרויקט
במסגרת הפרויקט יבחנו מגוון כלים אשר נמצאים בשוק, למשל:
- עבודה עם כלים לביצוע PROFILING לנצילות השימוש ב GPU[6]
- כלים ל MODEL INFERANCE [4,5]
- השוואת ביצועים בעזרת מדדים סטטיסטיים.
קורסי קדם:
- פיתון ברמה גבוהה
מקורות:
- https://openai.com/blog/introducing-chatgpt-and-whisper-apis
- https://bard.google.com/chat
- https://lmsys.org/blog/2023-03-30-vicuna/
- https://developer.nvidia.com/tensorrt-getting-started
- https://onnx.ai/
- https://developer.nvidia.com/nsight-systems/get-started
- https://developer.nvidia.com/nsight-compute
- https://numba.pydata.org/
- https://numba.readthedocs.io/en/stable/user/5minguide.html
- https://www.nvidia.com/en-us/glossary/numba/
- https://docs.python.org/3/library/profile.html#module-cProfile

{kind=link}